Upload File Requirements
- Your file MUST be comma-separated csv file
- Your file extension MUST be .csv
- Your file size MUST be smaller than 2.5MB
The CSV file format is below.
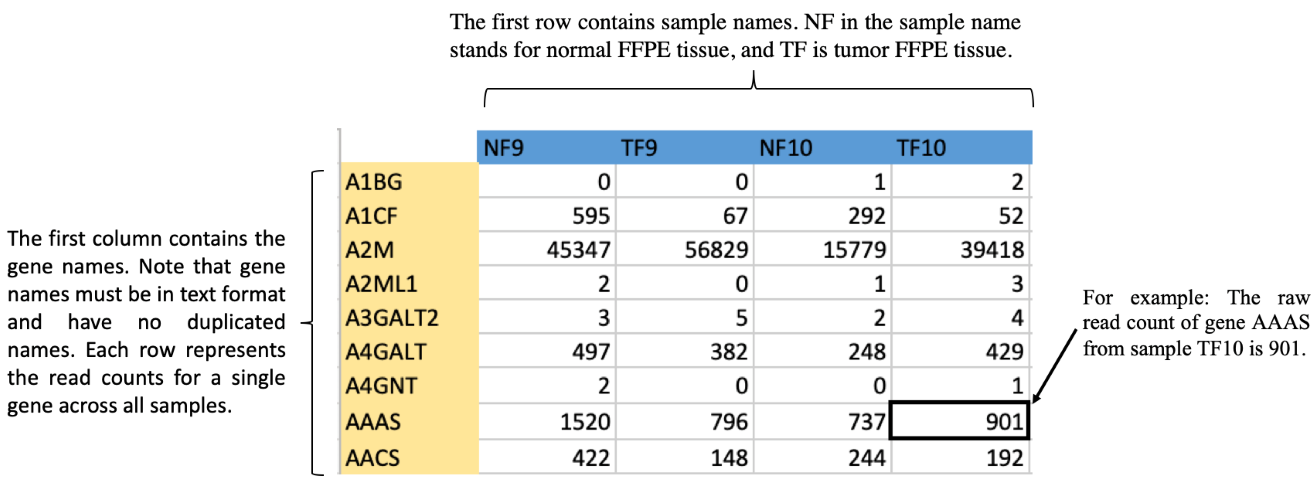
Download Example File
MIXnorm is based on a two-component mixture model, which intends to capture major characteristics of the FFPE RNA-seq data accurately. The non-expressed genes are modeled by zero-inflated Poisson distributions and the expressed genes are modeled by truncated normal distributions. A binary latent variable is assumed for each gene to indicate its expression status, i.e., truly expressed or not expressed. The maximum likelihood estimates of the mixture model are obtained by an efficient nested EM algorithm. The convergence is detected by the change of parameter estimates during consecutive iterations.
MIXnorm takes the raw count data as input and output the normalized expression matrix in natural logarithm scale. The default maximum number of iterations is 15 and the stopping criteria is 0.01. The exact MIXnorm uses the conditional probabilities of genes being expressed or not to produce the normalized data. The approximate MIXnorm uses a cut-off value of 0.5 on those probabilities to classify genes as expressed or not. Non-expressed genes will be normalized to 0 by approximate MIXnorm.