Upload File Requirements
- Your file MUST be comma-separated csv file
- Your file extension MUST be .csv
- Your file size MUST be smaller than 2.5MB
The CSV file format is below.
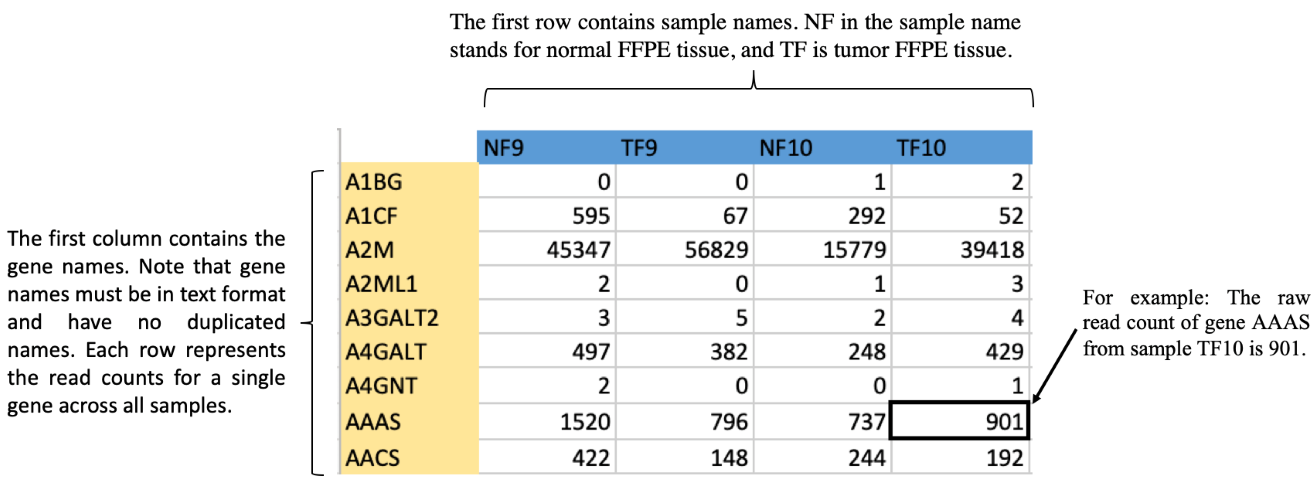
Download Example File
TMM is implemented in edgeR package. One sample is select as a reference and normalization is performed on the remaining samples against the reference. First calculate the M values as the log ratios of the read count between each test sample and the reference for all genes. The scaling factor is estimated by the weighted mean of M values after trimmed away the extreme M values.